

ANINHAMENTO COM FILTER E ROW CONTEXT
Se chegou neste post, peço que acesse o novo sobre Avaliação de contexto que está completo. Aqui.
Utilizar funções iteradoras dentro de outra, ou seja, aninhar, é uma prática bem comum no desenvolvimento de expressões em DAX e capaz de gerar boas análises.
O problema é que em algumas situações de uso, iteradores dentro de iteradores podem ser um pouco complexos de lidar, já que podem sair do controle gerando iterações além do esperado ou, ficando impossibilitado de referenciar valores externos àquela função.
Veja a expressão no exemplo abaixo. O PBI age da expressão mais interna para a externa, onde um row context trabalha para o outro.
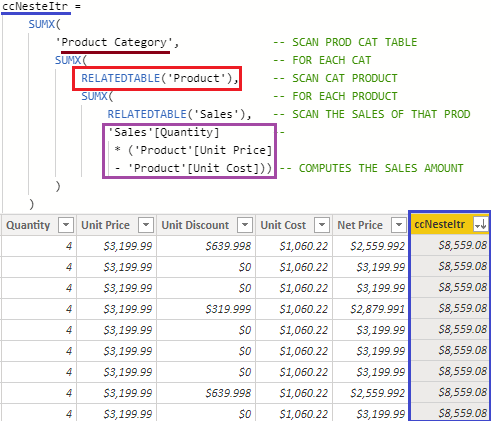
Explicação:
- A função SUMX recebe dois parâmetros que podem ser traduzidos por: chamada de ação(Table) e expressão(expression).
- A primeira ação é escanear a tabela ProductCategory, mas ao invés de criar uma expressão matemática, criei outra ação abrindo outro SUMX que escaneará a tabela Product.
- Neste ponto o que estou passando para o PBI é: “para cada categoria de produto, escaneie na tabela produto seus respectivos pertencentes”.
- Dentro do SUMX da tabela Product, abro outra ação para escanear a tabela Sales.
- Quando abro a ação para a tabela Sales aqui sim eu crio a expressão que retornará o resultado desejado.
- E aqui, a lógica ‘final’ é: “para cada Categoria de Produto, procure na tabela de Produto seus respectivos atribuídos. Para cada produto, busque na tabela Vendas as vendas totais destes produtos.
- Ao final, é só fechar os respectivos row context devolvendo os valores para cada uma dos contextos abertos.
Veja que aplicando esta mesma expressão em um filter context o resultado é bem condizente com o esperado. Fiz uma medida com a mesma expressão para criar uma “prova real”.
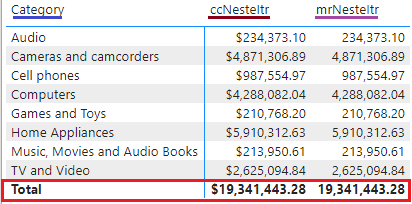
E se perceberem, na criação da coluna calculada chegamos a ter quatro row context abertos. Um para cada SUMX e o contexto automático da própria coluna calculada.
Existem casos onde o uso de um row context aninhado pode ser bastante problemático principalmente quando estamos trabalhando com colunas calculadas e iteradores. Essa situação fica delicada porque sabemos que uma coluna calculada quando criada, automaticamente cria um row context e, dependendo da função, teríamos outro.
Veja este exemplo abaixo:

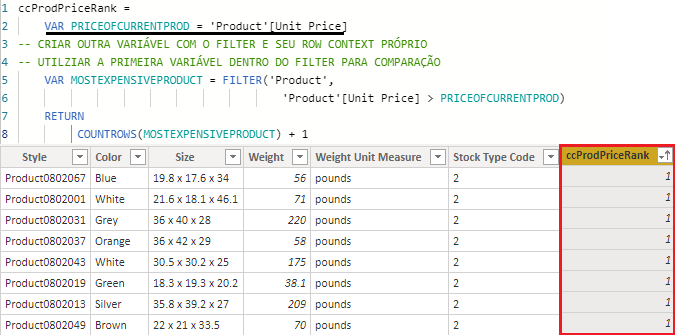
NOTA: a coluna priceofcurrentproduct não existe, foi posta ali apenas para exemplificação.
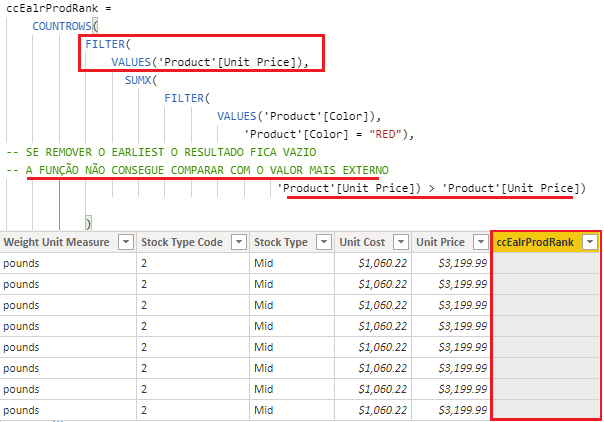
Se quiséssemos criar um ranking dos produtos mais caros dentro de uma coluna calculada, teríamos que comparar o preço do produto com o seu preço atual acrescer de 1. Como a função de FILTER acaba criando um outro row context para escanear a coluna, temos dois abertos.
Neste cenário de dois contextos abertos, a coluna interna não consegue referenciar a coluna externa ao FILTER; ficamos impedidos de criar a coluna com o filtro desejado. Então, a melhor maneira de resolver esse problema de aninhamento dentro de uma coluna calculada seria trabalhar com variável.
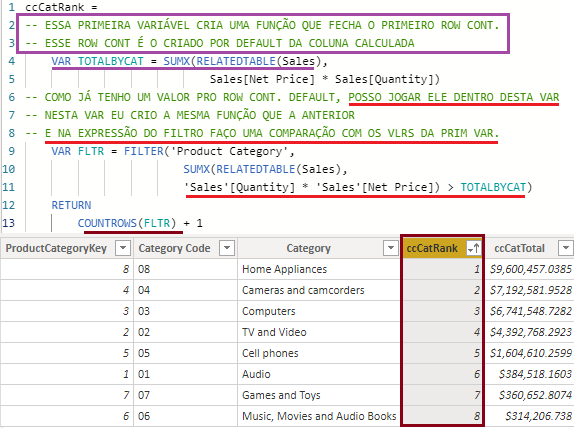
Qual foi a lógica desta solução?
- Quando criamos a variável PRICEOFCURRENTPRODUCT e lhe demos um valor, automaticamente esse row context é fechado e com ele fechado.
- Criamos outra variável com uma expressão e um novo row context, utilizando a primeira criada para comparar dentro do FILTER.
- Ao final, apenas utilizar o COUNTROWS para categorizar as linhas.
Existem funções específicas para ranking de objetos dentro do PBI. A intenção aqui foi apenas mostrar uma forma de solucionar uma situação que fatalmente irá ocorrer.
Então, sempre que for trabalhar com row context aninhados, utilize variáveis; principalmente se for comparar expressões internas com externas dentro do aninhamento.
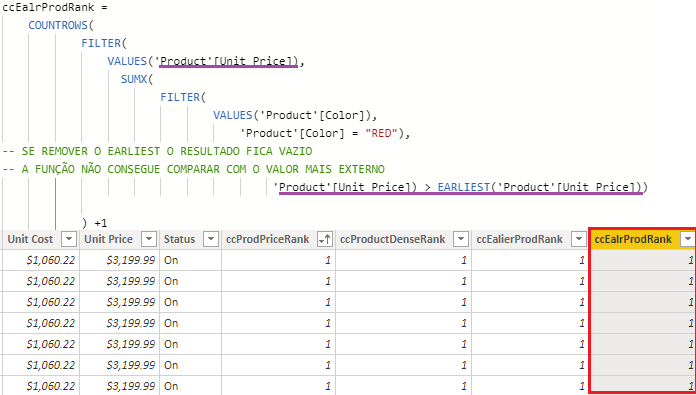
NOTA: Como o recurso de variável é recente, implementado em 2015, é comum alguns códigos antigos a isso possuírem a função EARLIER. Essa função consegue puxar o valor de um row context externo para um contexto mais interno.
E caso se depare com códigos muito aninhados, a função EARLIEST é a mais utilizada. Independente do nível, ela consegue puxar o primeiro parâmetro para a iteração mais interna existente.
Veja na imagem abaixo que a função não consegue comparar no nível mais interno os preços dos produtos.
Agora com a função EARLIEST, o mesmo resultado é obtido se comparado com os outros exemplos que vimos anteriormente.
FILTER, ALL E OS CONTEXTOS – CONCEITOS AVANÇADOS
Já vimos em diversas situações o uso das funções FILTER e ALL, onde a primeira é restrita para um tipo de situação e a outra limita a ação de um contexto de filtro quando aplicado em algum dashboard.
O que volto a reforçar aqui é que a função FILTER não cria um contexto de filtro, em nenhuma aplicação; ela é mais iteradora do que qualquer outro tipo. No máximo, ela restringe um contexto para um conceito.
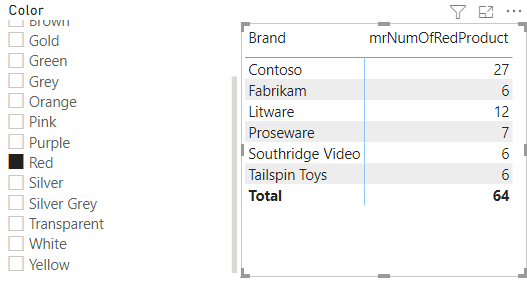
Na medida abaixo quero que ela retorne a quantidade de produtos vermelhos separados por marcas. Então, eu crio uma medida, utilizo a função o FILTER para RESTRINGIR e após, aplico em um contexto de filtro para segmentar as marcas.

Veja que a medida possui apenas uma tabela como base, que é a tabela produto. De forma resumida, o que o engine do PBI faz é aplicar um filtro dentro de outro, onde um maior (filter context) recebe um menor(função FILTER) e manipula conforme nossa vontade (aplicamos o contexto).
Agora perceba o que acontece quando jogo essa medida restrita de sua ação, pela função, em um gráfico de tabela com um slicer de cores para filtrar.
Selecionando qualquer outra cor que não seja vermelha, veja que não exibe nenhum valor.

O que muda quando seleciono a cor vermelha no slicer.
Retirando a restrição de cor e adicionando mais uma medida de contagem de produtos e o nome do produto no filter context, temos outro resultado.
Sobre a função ALL neste cenário, existe uma situação que pode ser indesejada quando ela interage com o contexto de filtro tornando o resultado bem estranho.
Ao criar uma medida com ALL aninhado na função FILTER o resultado de qualquer cor e marca de produto será sempre 99.

CONTEXTO ENVOLVENDO DIVERSAS TABELAS
Sabemos que assim como o modelo transacional, o dimensional também possui relações entre tabelas, ainda que diminutas.
Em modelos dimensionais bem estruturados, as relações costumam ser 1:N (um para muitos), garantindo a boa performance e estrutura.
Dentro do PBI o recomendado segue o mesmo, manter relações 1:N dentro dos modelos pois isso pode impactar diretamente os contextos de ação: row e filter context.
Nesta seção vamos entender como eles se comportam e quais os tipos de cenários que costumam aparecer.
Como temos 2 contextos e 2 estruturas de relação, o lado 1:N(lado Dimensão – Fato) e o lado M:1 (lado Fato – Dimensão), temos quatro cenários básicos para avaliação quando estamos estruturando ou executando uma expressão.
O primeiro cenário que vamos avaliar é o que envolve o row context.
Sua ação é feita linha após linha conforme o scan da tabela ocorre e embora uma determinada tabela possa vir a ter N relações, nenhuma destas consegue acessar ou tem um row context aberto.
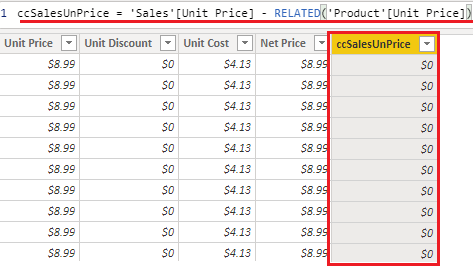
Veja neste exemplo, criando uma coluna calculada na tabela Sales relacionando com a tabela produto calculando a diferença entre preço unitário gravado nas duas.

Já é sabido que quando abrimos uma coluna calculada um row context é automaticamente criado para o cálculo e até então, por ser na tabela Sales, a expressão funciona perfeitamente. O problema passa a ser quando envolve a tabela Product, que mesmo com o relacionamento com a Sales, não participa do contexto pois está só de um lado.
Quando há esse tipo de situação, o que podemos utilizar como solução é a função RELATED. A função permite extrair os valores desejados da coluna da outra tabela para utilizar no contexto criado na tabela do lado many – to – one; no caso aqui, Sales -> Product.
A função permite referenciar apenas uma coluna por vez, mas é totalmente válido repetir a função na mesma expressão para criar cálculos diferenciados.
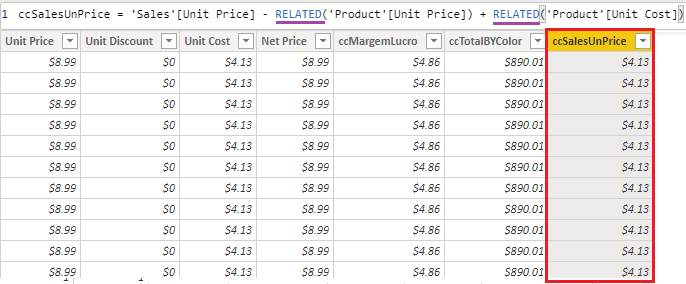
Só há um porém quando for utilizar a função RELATED: ela não funciona no lado one-to-many, no caso, Product -> Sales.

Como a função irá encontrar muitas linhas para um determinado código de produto, o row context não consegue processar a operação e retorna erro. Neste caso, o melhor é utilizar uma variação da função que se chama RELATEDTABLE.
Abaixo, uma aplicação do uso calculando a quantidade de vendas por produto. Como a função COUNTROWS é uma função agregadora e retorna um valor único para cada linha da tabela Product, temos seu resultado exibido e aplicado em um gráfico de tabela.

Não existe uma limitação quando utilizamos as funções RELATED ou RELATEDTABLE – limitação no sentido de relacionamento. Elas funcionam de forma bidirecional.
Em ambos, utilizando a função RELATEDTABLE foi possível criar medidas e colunas calculadas.
Se duas tabelas relacionadas possuírem entre si, uma relação 1-1, tanto RELATED quanto RELATEDTABLE podem ser utilizadas nas expressões.
Agora gostaria de chamar atenção para o seguinte cenário: imagine a seguinte relação.
- Product, Customer e Sales.
- Product -> Sales 1:N
- Customer -> Sales 1:N
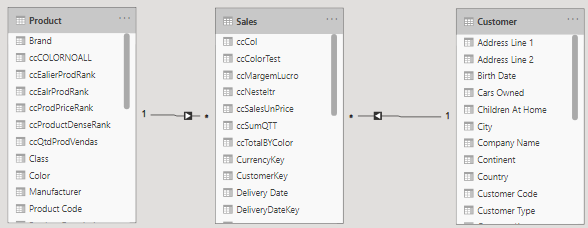
Sabendo que o fluxo de relacionamento pode ser seguido, poderíamos ligar Product -> Customer como uma relação M:N utilizando a função RELATEDTABLE.
Mas perceba que o resultado na coluna é a quantidade total de clientes que a tabela possui e não a quantidade clientes que comprou um determinado produto. Como a relação entre Product -> Customer têm direções diferentes, RELATEDTABLE não consegue seguir o fluxo
correto comprometendo o resultado.

Tenham cuidado com essas relações M:N caso utilizem RELATEDTABLE.
CONTEXTO DE FILTRO E O RELACIONAMENTO ENTRE TABELAS
Como sabemos o filter context é utilizado para segmentar valores de acordo com uma determinada situação, mas complementando essa ideia, o contexto não filtra apenas uma ou duas colunas em um painel, ele age sobre todo o modelo; apenas considera a direção da relação entre as tabelas.
Para ficar melhor demonstrado, vamos ver as três medidas em um contexto de filtro.
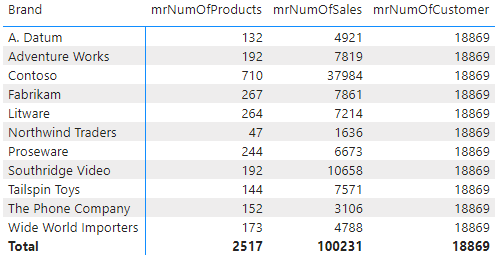
O que acontece nessa distribuição é que como a coluna Color pertence a tabela Product, que está no lado 1:N, o filtro age normalmente tanto com a tabela Sales quanto com a Product. Somente com Costumer que retorna apenas a contagem total de clientes por não conseguir alcançar a tabela, já que a relação Customer – Sales não é bidirecional.
Agora, uma maneira de solucionar essa situação seria criar um filtro com base nos clientes, mas mantendo as medidas.

Como o filter context mudou passando para Customer, e a relação Product -> Sales é bidirecional, conseguimos alcançar a tabela Product e categorizar a quantidade de compras de acordo com a escolaridade.
Caso o filtro não mude, basta alterar a direção na aba de modelo no PBI clicando com o botão direito na seta entre Product – Sales.
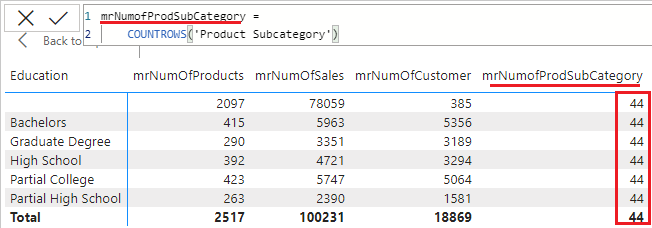
Tenha cuidado pois essa propagação do filtro entre as tabelas não se aplica às tabelas ‘filhas’. Por exemplo, se criássemos uma nova medida com a tabela Product Category, veja como o filtro agiria.

Como exemplificado anteriormente, para resolver essa situação, basta mudar a direção da relação Product – ProductSubCategory para BOTH.
CONCLUSÃO
Este foi um post bem extenso com muitos detalhes sobre como trabalhar com os contextos dentro do PBI, seja utilizando coluna calculada ou medida.
Tentei trazer o máximo de detalhes possíveis sobre o assunto pois não queria deixar nenhuma dúvida ou algo faltando nas explicações.
Dominar os contextos e como eles transitam entre as funções é fundamental para masterizar a linguagem DAX e seus detalhes e peculiaridades.
Sei que em algum momento o post pode ficar repetitivo, mas acredite, tem sentido. É para o completo entendimento do conteúdo.
Espero que tenham gostado do post, saúde!
