

Pensando em uma forma diferente de criar um portfólio para engenharia de dados, comecei a pesquisar algumas ferramentas que estão entre as mais utilizadas do mercado e me deparei com DBT.
Como acrônimo para Data Build Tools, a ferramenta construída em Python com base no Jinja facilita a criação de modelos de dados com base na linguagem SQL e Python.
Outro ponto que me chamou a atenção e me fez decidir pelo seu uso é a facilidade de criação de modelos que podem ser utilizados por diversos times sem que haja grandes mudanças, além do fato desses modelos, desde que com a mesma base, entregarem o mesmo resultado – o que é execelente para uma ferramenta e ELT.
O DBT age na etapa de transformação, podendo criar novas tabelas e análises com base nos dados brutos.
Desse modo, quero trazer para vocês os primeiros passos e configurações e compartilhar meu aprendizado e futuro portfólio com ele.
Espero que apreciem. Vamos ao post!
ÍNDICE DO CONTEÚDO:
INSTALAÇÃO DO DBT
DBT é uma ferramenta criada para executar transformações através da linguagem SQL.
Muito utilizado como o T do ELT, foi desenhado para transformações e manipulações de dados que estão no servidor de banco.
Baseado em templates no formato YML, ele facilita bastante o desenvolvimento e processamento de queries, tendo conectividade com quase todos os fornecedores de banco de dados.
Para começar a instalação, tenha na máquina o gerenciador de pacotes Python chamado PIP.
Com o gerenciador PIP, siga os passos abaixo:
- Crie uma pasta para o DBT e mude para o diretório com o change directory (cd).
- Na pasta, digite no terminal:
python -m venv dbt-env.
- Ele irá demorar um pouco pois estará criando o ambiente virtual para o DBT. Quando terminar de criar, na pasta do DBT haverá uma nova chamada dbt-env.
- Ative o ambiente virtual do DBT com o seguinte comando:
source dbt-env/bin/activate
- Com o ambiente ativo, instale o dbt-core copiando e colando o comando abaixo:
git clone https://github.com/dbt-labs/dbt-core.git
- Ao final da instalação pela fonte, a pasta dbt-core estará no diretório. Mude para ela com o comando: cd dbt-core
- Na pasta dbt-core, digite no terminal:
pip install -r requirements.txt
Ele instalará os seguintes plugins e arquivos: dbt core, postgres, redshift, snowflake e bigquery.
IMPORTANTE: todo esse processo deve ser feito no dbt-env.
NOTA: como utilizo a versão do Python 3.10 no meu ambiente de estudos, utilizei o seguinte comando:
pip3.10 install -r requirements.txt

Veja que na minha pasta DBT, há dbt-env e dbt-core. Conforme instalado nos passos anteriores.

Agora que os requisitos básicos para o uso do DBT foram criados, vamos iniciar um projeto.
Quando iniciamos um projeto com o DBT, ele traz um template pronto com as pastas e os paths, além de um arquivo de configuração do projeto.
Para criar esse template do DBT, execute o comando: dbt init <nome do projeto>

Abaixo, parte do arquivo YML de configuração:
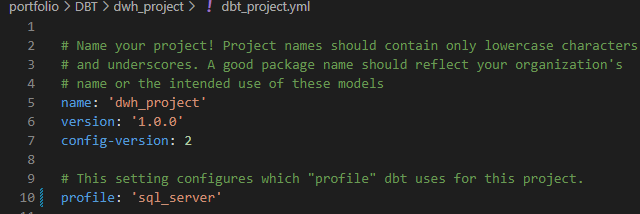
Uma dica que eu dou é para criar a sua pasta de projetos fora da pasta DBT onde foi feita a instalação dos pacotes e arquivos necessários.
Instalado as dependências necessárias para começar a desenvolver os projetos, agora temos de configurar o profile ao qual seu arquivo do DBT criado com o dbt init, irá buscar as informações para conectar com o banco.
CRIAÇÃO DO PROFILE
O arquivo de profile é um template para conexão do DBT com os bancos de dados. Ele pode conter diversos profiles de conexão, um para cada banco ou ambiente de destino diferente.
Com o template criado no profile, no projeto, basta referenciar o nome da conexão com os parânetros criados que o próprio DBT irá localizar e se conectar.
Esse ‘mini-profile’ deve conter as credenciais corretas de acesso ao banco informado.
Antes de começar a configuração do Profile.yml para o DBT funcionar, precisamos saber de onde ele está procurando o arquivo.
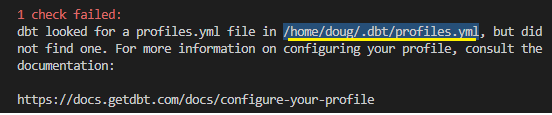
No meu caso, como estou utilizando o WSL2 com UBUNTU, o DBT busca neste diretório.

No terminal, utilize o change directory (cd) para chegar até ele:

Como não havia o arquivo no diretório, precisei criar um com o comando touch.
O profile deve conter as informações do banco ou lakehouse que irá utilizar. Como utilizarei o SQL Server na minha máquina local, criarei uma configuração para ele nesse arquivo.
Antes, confira se no seu Linux, caso esteja utilizando, está com o drive ODBC instalado com o comando:
sudo apt install unixodbc-dev.

Como extra para caso esteja utilizando alguma distro Linux, aconselho a instalar o drive odbc do SQL Server no seu S.O utilizando este tutorial da MS.
O link irá para a página de instalação do Linux, basta escolher o que se adequa a sua distro.
A versão que instalei no meu sistema foi a mais atual, ODBC 18.
Quando terminar de instalar, aconselho a atualizar o gerenciador APT, caso esteja em uma distro que o utilize.
Sudo apt update && apt upgrade.
Uma vez instalado o driver, adicionei o diretório que o comando instalou a variável de ambiente.

Para tal, basta utilizar o comando:
export MSSQL_DRIVER=/opt/microsoft/msodbcsql18/lib64
E após o: source ~/.bashrc
CONFIGURANDO O PROFILE
Com o arquivo do profile criado, você precisará passar as configurações do banco de dados que irá utilizar.
Como estou utilizando o SQL Server, essas são as configurações que estou criando no momento.
Você pode abrir o profile no próprio VScode e configurar.

Aqui, eu quero chamar atenção para algumas situações:
- SQL Server → sublinhado em vermelho é o “nome” desta configuração que está armazenada no profile. Perceba que tudo que vem abaixo são subnós do nó raiz.
- Type → é o banco que estou utilizando para a configuração e criação do portfólio.
- Driver → parte importante da configuração do arquivo. Se seguiu os passos corretamente, a própria ferramenta irá localizar e utilizar o driver adequado.
- Port → dentro do seu Configuration Manager do SQL Server, é possível descobrir a porta. Caso esteja em default, é 1433.
- Server → Não adianta utilizar o nome do host e o server name do banco, nos meus testes, eles deram erro. Para conectar, precisamos do IP.
- Trust_cert → como por padrão é false, é necessário adicionar esse parâmetro na propriedade como true. Do contrário, acusará erro de conexão por não ter segurança.
Caso não saiba, para descobrir a porta do SQL Server, vá nas informações do seu servidor instalado acessando Configuration Manager.
Na aba em vermelho.

Caso esteja utilizando o WSL com Ubuntu como substituto de máquinas virtuais, necessitaremos do IP do WSL para conectarmos com o banco de dados.
Para isso, abra o cmd do seu Windows e digite: ipconfig.

Esse endereço de IP é o que irá no arquivo Profile do DBT que criamos.
Quando terminar essa configuração primária, faça o teste de conexão com o comando: dbt debug.
Abaixo, o resultado do teste:

Uma vez que o teste foi realizado, faça um novo teste de execução, desta vez, utilizando o comando: dbt run.
Este teste irá utilizar os modelos de exemplo que o DBT tem quando criamos o nosso projeto.
Ele executará um dos modelos e criará uma tabela no banco passado no profile.

Caso o seu teste apresente a seguinte mensagem de erro, será necessário modificar a configuração do servidor do SQL Server.
('42000', '[42000] [Microsoft][ODBC Driver 18 for SQL Server][SQL Server]This index operation requires 81736 KB of memory per DOP. The total requirement of 81736 KB for DOP of 1 is greater than the sp_configure value of 1024 KB set for the advanced server configuration option "index create memory (KB)". Increase this setting or reduce DOP and rerun the query. (8606) (SQLMoreResults)')
Solução para a mensagem de erro:

Uma vez que tenha solucionado o erro da mensagem, execute novamente o comando: dbt run.

Uma observação que para o projeto em questão, eu criei uma conta pro DBT no banco de dados:
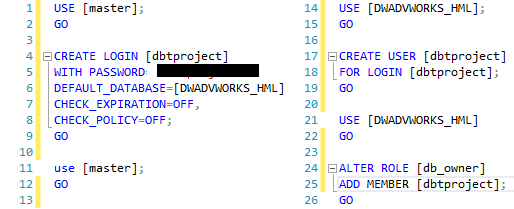
Um outro erro que pode ocorrer na configuração do DBT durante o teste de debug é o connection timeout.
Caso tenha configurado tudo corretamente, com os devidos acessos, talvez seja necessário desativar seu firewall na central de segurança do Windows.
No meu caso, como estava tentando conectar com uma ‘máquina virtual’ no localhost, o S.O estava impedindo a conexão com o SQL Server instalado em minha máquina – mesmo com o trust_cert ativado. O que acarreta na mensagem de timeout.
Após desativar o firewall, faça novamente o teste com o dbt debug e veja se a conexão ocorre.
CONCLUSÃO
Neste post mostrei como instalar a ferramenta DBT para transformar dados direto da fonte via comandos SQL além da configuração básica do projeto para o primeiro portfólio.
Vimos como conectar com o banco de dados SQL Server além de instalar os drives internos necessários, bem como do Spark, caso vá utilizar – como é o meu caso.
Muito cuidado com a criação do Profile para não criar uma configuração errada e obter falha no projeto.
O DBT é uma ferramenta de transformação e, em certo modo, modelagem como código. Muito útil para equipes de dados trabalharem de forma colaborativa.
Espero que esse artigo os ajude! Obrigado!
Não esqueça de curtir e compartilhar. Me ajude a alcançar mais leitores!
Não esqueça de assinar a newsletter!
