

Olá pessoal, tudo bem?
Retomando o projeto de portfólio do data warehouse e as cargas na dimensão, neste post quero mostrar como elaborei todo o pipeline de carga da dimensão e os processos de normalização da tabela que envolveram desde a extração na fonte até o processo de implementação do slowly changing dimension.
DIMENSÃO FORNECEDOR – SUPPLIER
A dimensão tem a intenção de analisar todo o processo de compra com fornecedores de materiais para a produção de produtos a serem vendidos.
A ideia é ter uma base com os melhores no quesito prazo e preço, estabelecendo uma relação de fidelidade com os melhores fornecedores.
Este foi o meu pipeline de transformação inicial para adequar os dados que vieram da área de staging após a extração primária do modelo relacional.

Essa transformação em si não tem grandes destaques, por ser uma tabela bem simples, há pouco a se fazer aqui, o que podemos destacar é o gerenciamento das surrogate key da tabela pelo step add sequence.
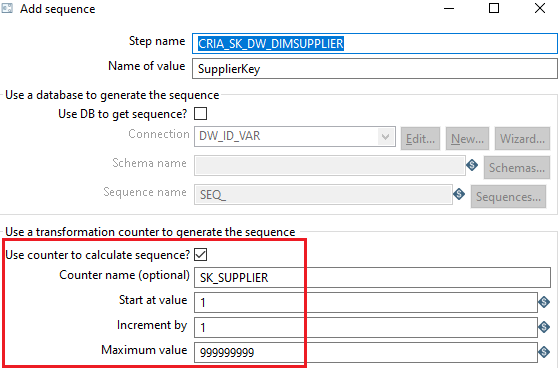
Além,a normalização dos endereços e nome dos fornecedores transformando as abreviações em nomes completos, diminuindo qualquer possibilidade de ambiguidade.
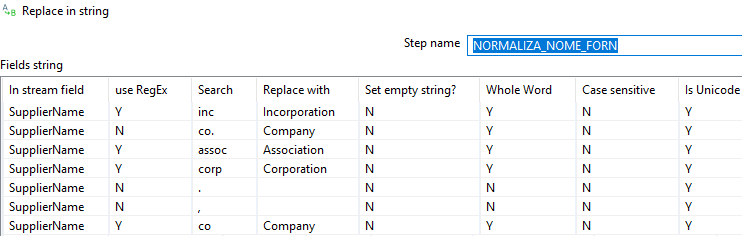

A configuração foi bem simples, e não criei nenhuma sequence no banco. (Aqui e aqui estão posts sobre o uso de sequence).
CONFIGURANDO O SCD TIPO 1
O slowly changing dimension tipo 1 é o modelo de controle de mudança que não armazena registro histórico.
No PDI esse tipo de SCD é gerenciado por duas transformações:
- Insert/Update.
- Dimension Lookup/Update
Nesta dimensão vamos conhecer o step Insert/Update e como configurá-lo.
O step permite tanto atualizar como simplesmente inserir na tabela sem gerar nenhuma atualização, veja.

Como podemos ver, a transformação tem uma certa mistura de lookup com table output, ao mesmo tempo que ela pesquisa e compara um valor vindo da stream com a fonte/destino, também permite que se insira dados pelas configurações de conexão no início.
No destaque em vermelho da imagem da transformação, temos a configuração da conexão com o banco e a tabela que inseriremos os dados.
Vale destacar ali o commit size que coordena a quantidade de linhas que irá comitar durante a carga. Ajuste conforme sua necessidade.
Em destaque arroxeado, temos os campos que utilizaremos como comparação para os processos de scd propriamente ditos. O ideal e boa prática do processo, é utilizar a chave primária do banco relacional, também conhecido como natural key.
Como ela não se altera no banco de dados, é extremamente confiável de se utilizar para esse controle.
Dentro do step, sublinhado e destacado em azul, temos a configuração da ação que a transformação irá realizar.
Se marcarmos a checkbox “don’t perform any update” a tarefa simplesmente irá inserir como um novo valor qualquer alteração que ocorra. Do contrário, irá atualizar.
Já na coluna update no campo update fields, escolhemos quais colunas serão atualizadas ou não, pelo step.
Como é a primeira carga no data warehouse, deixei desmarcado e executei o processo de ETL.

SCD NA PRÁTICA
Agora vamos ver alguns testes para entendermos como essa transformação com o controle de mudanças se aplica.
Primeiro passo foi alterar o arquivo txt que foi utilizado como fonte para carga do data warehouse. Alterarei o PostalCode de um fornecedor e carregarei essa mudança para o banco.

Antes de realizar a operação, fiz um select no banco para mostrar que os valores ainda não foram alterados.

Na transformação Insert/Update deixe desmarcado a caixa de diálogo “don’t perform any update” e na coluna PostalCode, marque com “Yes” a coluna update.

Percebam que o próprio log da transformação informa que houve update na carga de dados no dw.
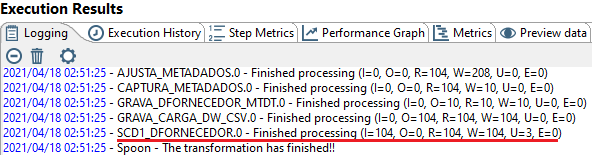
E após a carga, realizei um novo select no banco onde podemos ver que a coluna foi devidamente alterada.

E mesmo que todas as colunas estejam configuradas para realizarem update quando sofrerem mudanças, se a caixa de diálogo estiver marcada, a transformação não atualiza, não importando qual valor seja alterado; apenas insere dados.
CONCLUSÃO
Este foi o primeiro post do meu primeiro portfólio onde realizei uma carga direta em um data warehouse com as devidas transformações.
Por ser uma dimensão pequena e com poucos dados, não houve uma grande complexidade na estruturação do ETL, a parte mais difícil aqui é normalizar endereço.
Tenha cuidado quando for implementar esse SCD para não alterar as natural Keys e perder a referência de comparação.
Se for utilizar este modelo, que seja em tabelas que o histórico não é importante, como podemos ver, aqui não há nenhum histórico de mudança, o Pentaho somente sobrescreve o valor e finaliza a tarefa.
No mais, é uma boa forma de controlar mudanças em tabelas pequenas e sem importância, com uma boa liberdade no que se vai ou não atualizar.
